The past weeks were about understanding where and why our (metric) diffusion model lacks behind SOTA (but trained on clear weather data) MMDE models, namely UniDepthV2 and DepthAnything3.
The most unintuitive finding was that both SOTA models actually improved in (especially near-field) performance given a dataset with (synthetic) fog vs it's clear counterpart, i.e.:
Note, that this was ALL done on the real-drive-sim dataset, which does have high-resolution (1x2K pixels) monocular inputs. The haze that wa sproduced however, was plain (uniform scattering coefficient and atmospheric light) uniform fog.
Surprisingly, our model that was trained exclusively on the foggy real-drive-sim dataset now showed improvements in real world data, namely the muses dataset.
We get across the line big improvements on the delta1, the MAE and RMSE scores. Even against the (now actually "Better" working clear split into UniDepthV2 predictions, which only holds a better score for Delta1 scores)
Note: The muses dataset uses "reference" frames where it tries to overlay clear weather images with those taken in hazardous conditions. The reference images do NOT perfectly align, nor do other conditions (i.e. other traffic participans) match. Still, apparently UniDepthV2 preformans better on the reference frames - evaluated AGAINS the LiDAR point cloud of the "GT" RGB frames (from the foggy scenes). All benchmark scores above are taken between 0-80 meters, where we do hope for the LiDAR to be robust enough even in foggy scenarios.


Now still, the question is where our model falls short in the simulated case. Most likely we can rule out anything about the pixel distribution in the simulated world vs how the real world looks, but rather look at the simulated fog.
Note that across the board, all models increased their performance in a direct fog vs clear comparison - which was inverted in the real world data case, even though the clear data was absolutely less aligned with the LiDAR scans.
Now it is time to actually apply the most sophisticated (that can be done in reasonable time) fog simulation model and see how the directional performance differences behave.

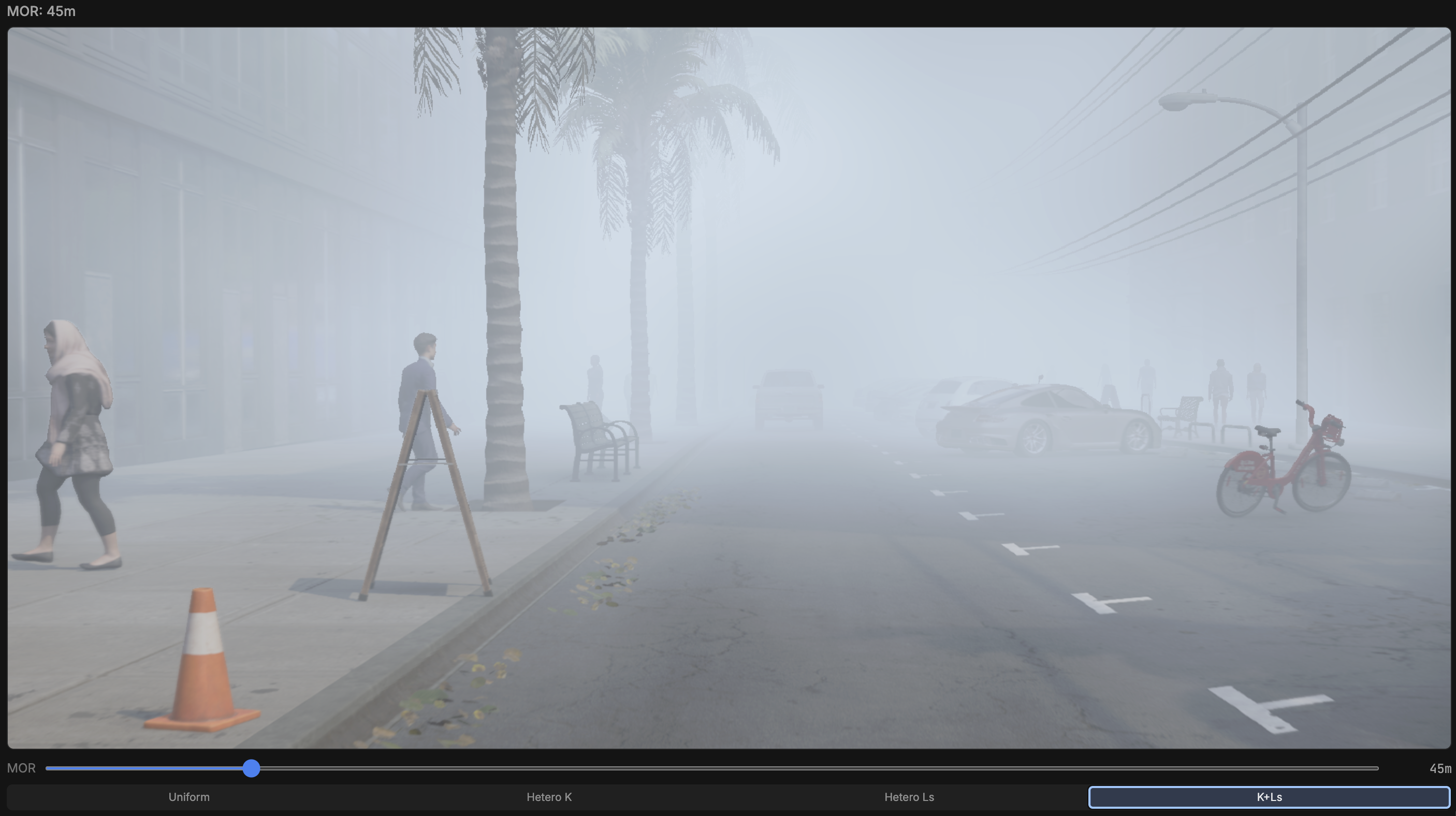
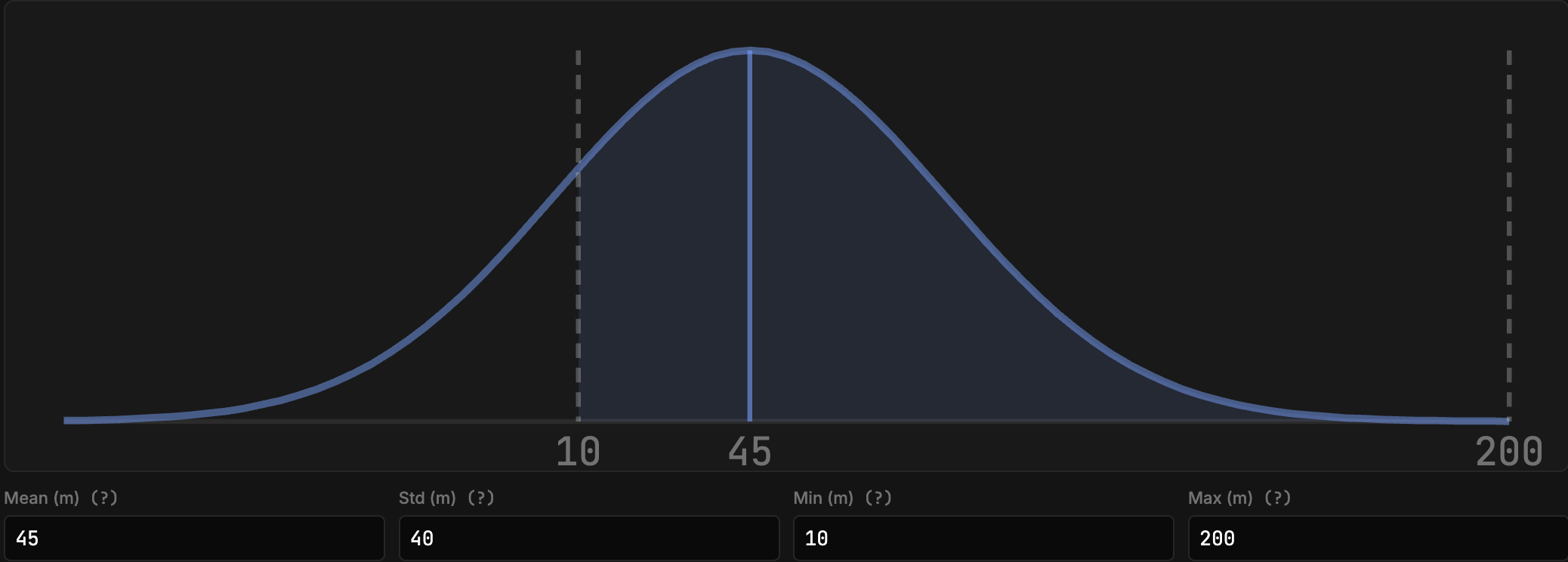
Now, even with a (Perlin noise) spatially varying scattering co efficient and atmospheric light (intensity) we get:
Sensor Noise Model
The next idea was to consolidate both heterogenous fog settings, with progressively more aggressive image deterioration - modelling a camera's sensor pipeline.
Given the added augemntations of training data, we see further improvement on real world datasets - though SOTA models, e.g. UniDepthV2, stay ahead in the synthetic evaluations.
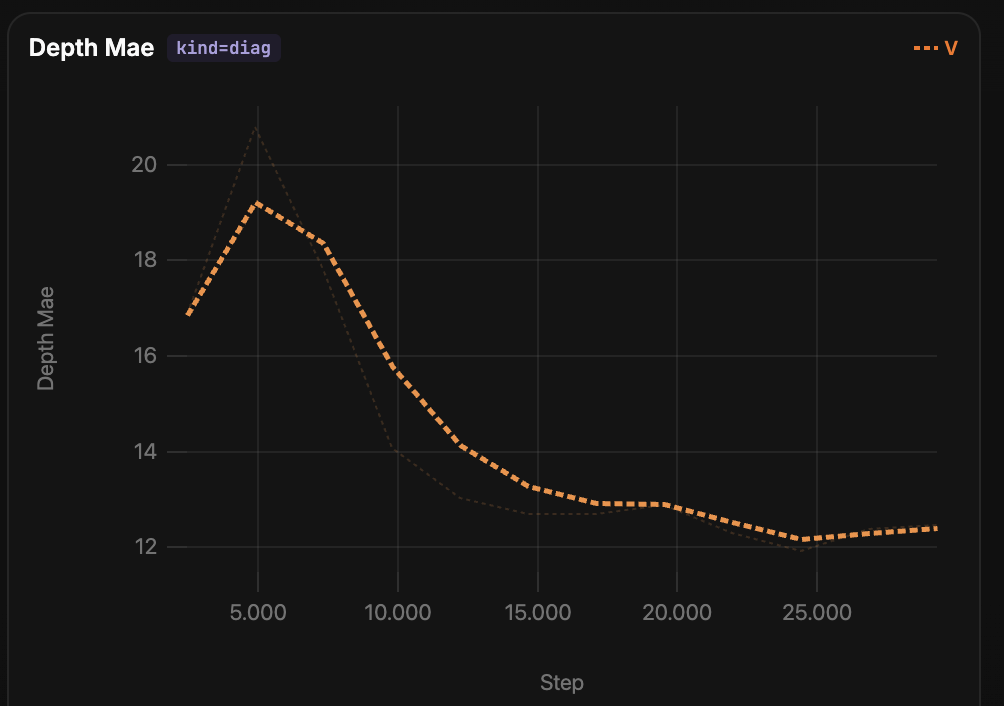






I notice that smoothness of depth predictions in real data, e.g. muses, thus dös drop - however we do now in part render in chromatic noise to the dehazed images. Though we finally get pseudo-realistic inpaintings behind the fog wall:

